AWSへの全面移行を進める理由 〜日本最大級の不動産ポータルを運営するオウチーノさまにインタビュー(前編)〜
2017年3月27日 月曜日 | WORKS
こんにちは、安田です。
このたび、弊社インフラサービスのお客さまでもある株式会社オウチーノさまにWeb会議のスタイルでインタビューをさせて頂く機会を頂戴しました。

オウチーノさまは住まい探し・リフォーム・注文住宅の分野で高い専門性を強みとするサイトを運営していらっしゃいます。インタビューでは、レキサスがお手伝いさせて頂いた同社WebサービスのAWSへの全面移設について、関係者全員で振り返る良い機会となりました。
現場のあるあるや実際に苦労したところなど赤裸々に語っていただきましたので、以下にその内容をお伝えしたいと思います。
【対談者紹介】
加藤さま:株式会社オウチーノ システム開発 Div. リーダー
國友さま:株式会社オウチーノ システム開発 Div.
下門:株式会社レキサス クラウドインテグレーションチーム テクニカルセールス
与儀:株式会社レキサス クラウドインテグレーションチーム AWSソリューションアーキテクト
河村:株式会社レキサス 東京オフィス マネージャー
安田:株式会社レキサス コーポレートデザイン部 広報担当
1.AWS移行前のネットワークの課題
■河村
今日はどうぞよろしくお願いいたします。今回はオウチーノの提供するWebサービスのインフラをAWSに全面移行しようとする取り組みについて、インタビューを2回に分けてリリースしたいと考えています。まず第1回目はネットワーク・プロキシサーバ移行の話をお聞きしたいと思います。
ではさっそくですが、オウチーノがWebシステム全体をAWSに移行するという流れの中で、ネットワーク側での課題はなんだったのでしょうか?
■加藤
ネットワークトランザクションの大部分が、かなり遠回りな構成になっていたことが挙げられます。

■河村
遠回りというと、具体的にはどういう状況だったのでしょうか?
■加藤
主だったシステムはデータセンターにあったのですが、AWS上にも一部のサービス環境がありました。ドメインのエンドポイントはデータセンターだったので、AWS上のサービスへは「データセンターで受けてAWSへ転送し、またデータセンターを経由して出て行く」という、すごく遠回りな形になっていました。
【AWS移行前の構成】
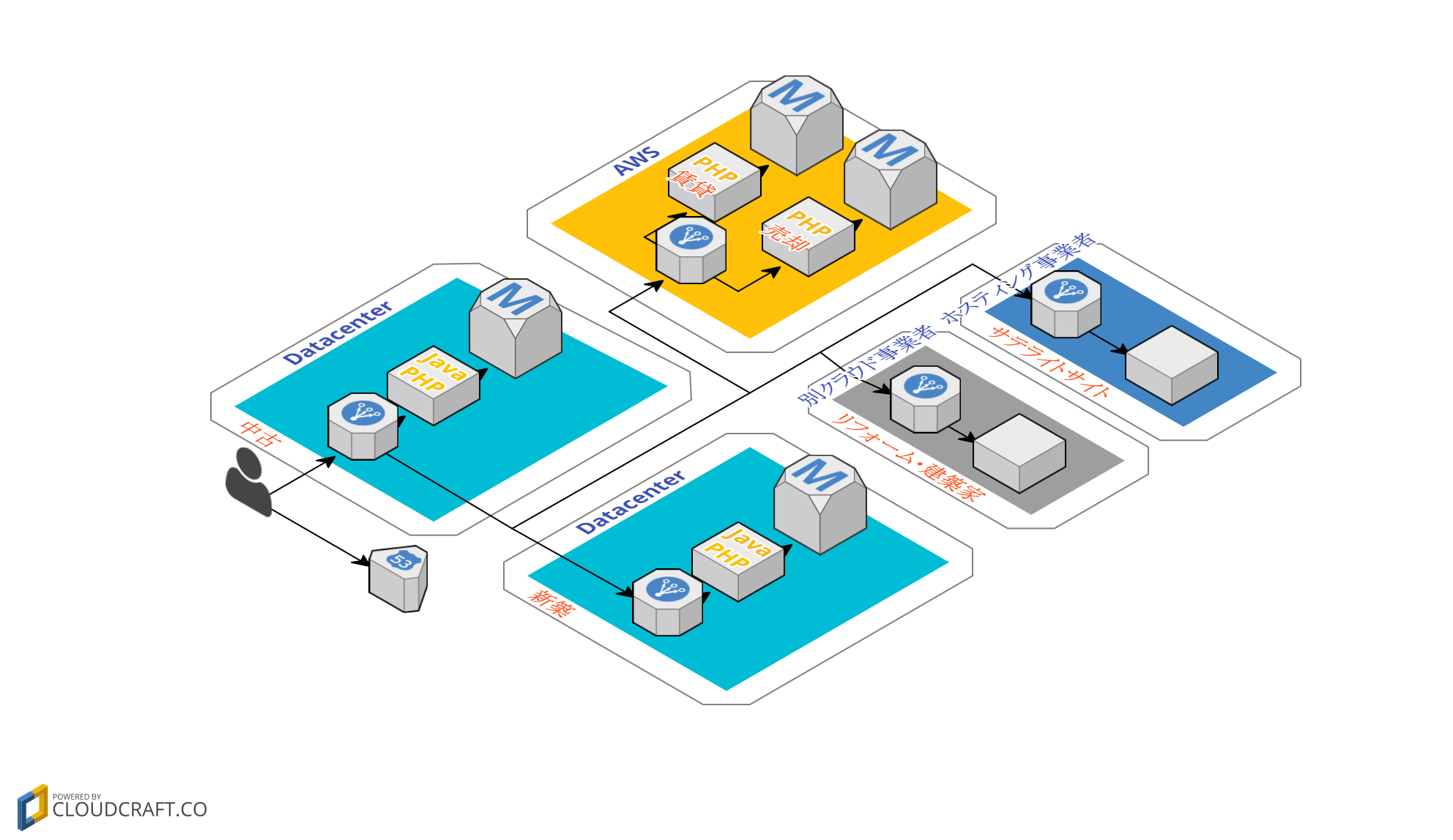
(↑クリックで拡大します)
■河村
だいぶ遠回りですね。
■加藤
また、今回はHTTPSの証明書の規格が変わるということで、2016年12月末までにSHA-2対応をやり終える必要がありました。
ただ、データセンター側でサービスを稼働させながらSHA-2対応を行っていくのは難しかったんです。物理的にも時間的にも厳しく、もうゲートウェイをAWS側に持って行って、そこで全部対応しよう、という話になりました。
■國友
ゲートウェイがAWSになかったり、構成上の問題点としてデータセンターにあるリソースとAWSにあるリソース、それにまた別のクラウドも使っていたのですが、そちらのリソースと、管理がうまくいっていない状況もありました。今回AWSを中心としたネットワークに整理することで、それらのリソースの統合ができたこともよかったです。
【AWS移行後の構成】
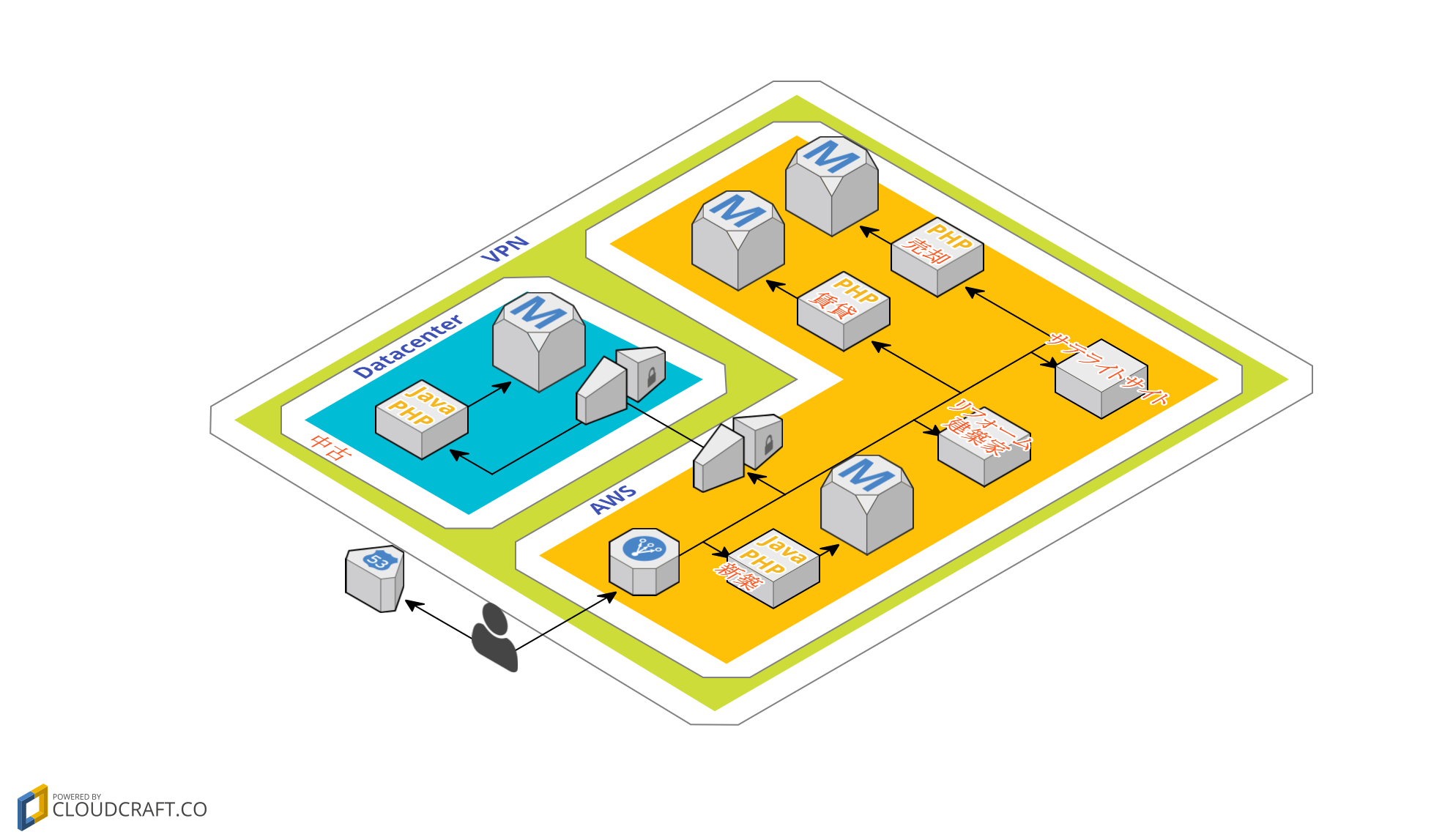
(↑クリックで拡大します)
AWSへの移行で年間600万円のコスト削減
■下門
今後、全面的にAWSに移行するということを見据えたうえで、AWSを入り口にしましょうということになったのですね。そもそもシステムをAWSヘ移行しましょう、となった背景はどんなところにありますか?

■加藤
まずコスト面の課題がありました。データセンターに大きく2つのセグメントがあり、それぞれがインターネットへのエンドポイントを持っていたので、ランニングにかなりコストがかかっていました。それをAWSに集約して、AWSをフロントにすることでコスト削減を図りました。
また、データセンターのサーバメンテナンス用に、Webで参照する回線とは別の回線を引いていました。セグメントごとに参照用とメンテナンス用で2回線、全部で4回線も持っていたんです。これがフロントにAWSを立てて、ひとつにまとまりました。かなりのコスト削減につながりました。
他にも、レガシーだったものを載せ替えることで最適化を図るなど、色々な面でお手伝いいただき、AWSへの移行前と比較して年間で約600万円のコスト削減につながりました。
AWSに移行して良かったこと
■下門
ハードウェアの故障や保守期限の課題感もありましたか?
■國友
保守期限が迫っているサーバがかなりの台数を占めていたので、ハードウェア故障による障害対応が多かったのは確かです。ですが、少なくとも1セグメント分はAWSへ移設できましたので、「データセンターへ行ってきます!」という状況はだいぶ減りました。

■河村
移行する期間についてなのですが、オンプレtoオンプレと比べて、オンプレtoクラウドはだいぶ違いますと思うが、実際にはどうでしたか?また今回のネットワーク・プロキシサーバ移行を実施して良かったことはありますか?
■加藤
移行期間については実質1ヶ月でした。良かったことは、ネットワーク構成がシンプルになったことです。作業者にとってはそこが一番大きいです。その結果いままでの構成では4か所あったエンドポイントが、AWSに移行したことでひとつになったため、障害発生原因の切り分けや対応の速度が上がり、安全性、耐障害性を上げることができました。
もちろん、管理も楽になりました。また、Certificate Managerを使えるようになったおかげで、サーバ1台毎に証明書を入れるという作業が不要となり、SSL証明書の管理がだいぶ楽になりました。証明書の期限のたびに証明書のインストールで慌てることもなくなりました。ライセンスのコストも10ライセンス分は削減できました。
AWSとデータセンターの併用ノウハウいろいろ
■下門
現在はAWSにゲートウェイがあってそこからデータセンターにもDirect Connectを使って繋いでいますよね。
■加藤
はい、「ホワイトクラウド ダイレクトアクセス for AWS」を使ってソフトバンクの閉域網に繋いでいます。
■下門
「ホワイトクラウド ダイレクトアクセス for AWS」を採用した背景があれば教えていただけますか?
■加藤
データセンター側で利用していたN/Wアプライアンス機器のH/Wのところです。こちらにロードバランサーとIPS/IDSの機能が入っており、同じベンダーの機器で閉域網に繋げられるとのことでしたので、当初はこの機器を利用する予定でした。

■國友
今回のネットワーク移設で、そのアプライアンス機器を使ってデータセンターとAWSを閉域網で繋ごうとしていました。ですが、AWSとの接続で弊社のサービスを載せるにはちょっと難しい課題が出てしまいまして、急きょ検討した結果ホワイトクラウドの閉域網に乗り換えたんです。
AWS上で構築を予定しているプロジェクトが走っており、切り替えタイミングがずらせないというのは大きな壁でした。ですので、たまたま弊社が使用しているデータセンターがソフトバンク系列の施設だったこともあり、閉域接続するまでに相当短い期間でできるという点は、決断を大きく後押ししました。
これは予想していなかった・・・赤裸々な苦労話あれこれ
■加藤
直接繋いだことで苦労話もあります(笑)。AWSからデータセンターに入ってくるインバウンドの通信については問題ないのですが、データセンターからAWSを通って外に抜けようとするアウトバウンドの通信が通らなかったんです。まさかそんな事態が起こるとは思わず、データセンター側のインターネット回線も全部解約してしまったので…。結局、ご提案頂いてAWS側に急遽中継サーバを用意しました。そこが一番苦労した点です。
■國友
設計を詰める段階でのいる/いらないの取捨選択の時、閉域網があれば大丈夫だろうという判断をしていたのでデータセンター側のインターネット回線はすべて解約しました。実際にはAWSから直接は返信できるのですが、閉域網を通ってデータセンターへ送信し、もう一度閉域網を通してAWS経由で外に返信する、というのができなかったんです…。運用に乗せるまで、旧環境の回線は残しておいてもよかったな、という反省はあります。結局作業のオーバーヘッドが出てしまいましたので。
■下門
インバウンドの通信はある程度検討できていたものの、アウトバウンドの通信はあまり考慮できていなかったということですね。
■河村
与儀さんがこの点で苦労したことがあれば教えてください。
■与儀
そうですね、弊社側でもその点についてあらかじめフォローできていれば良かったのですが、確認が遅れてしまったということはあります。それから、データセンターから出るために、多少強引ですが、急遽AWS上にDeleGateでプロキシサーバを立てて、iptablesでNATを構築して、と、弊社山川がうまく対応してくれました。

■加藤
プロキシサーバを立てるのも一筋縄ではいきませんでした(笑)。かなり古いシステムだったため中身がブラックボックスで、どの通信プロトコルが発生しているのか分からなかったんです。これを1から2週間モニタリングして「このプロトコルしか通ってない」というのを確認して、じゃあ中継サーバでいけるんじゃないか?と多少リスクを負って踏み切りました。
■下門
ですね、モニタリングしましたね(笑)
■加藤
切り替えのタイミングがずらせず、もう時間が無かったので・・・。
■國友
あとは、データセンターとプロキシサーバで繋いだことについての話ですが、当然データセンター側のWebサーバは複数台あり、VPC環境下なのでELBを使ってバランシングできないか、と考えたんですができるはずもなく(笑)。そこからはまたご提案いただいて、プロキシサーバにプロキシバランサーのApacheモジュールを入れ、そちらを使って振り分けをするという構成にしました。
■下門
プロキシサーバは元々データセンター側にもあったのでしょうか?
■加藤
ありました。ただバランシングの役割はなかったんです。今回、ELBのかわりにプロキシサーバに同居する形でモジュールで追加しました。サービスごとにドメインが分かれていた頃の構成を、1つのドメインに統合後もそのまま引きずった構成になっていて、アプライアンスとプロキシサーバで色々な役割を分担していました。そのため、2台あるプロキシサーバのコンフィグが2系統存在するという、変則的な形になっていたんです。間違って上書きしたら…というプレッシャーも大きく、メンテナンスにはかなり気を使う状態でした。
■國友
もうひとつ落とし穴があったのは、セキュリティの部分です。以前のデータセンター側の構成ではIPS/IDSのアプライアンス機器を導入していたのですが、AWSへ移行するにあたりCloudFront+AWS WAFで解決しようと考えました。ですが、大量のデータ検索処理を必要とする部分で、一定以上の応答時間がかかる処理があったんです。そのロジックを流すとCloudFrontがタイムアウトする現象があり、このままではサービスの提供ができない、どうしよう…と。カットオーバーしてから見つかって、突貫で対応しました。
■下門
これは世の中的にもバッドノウハウとして喚起したいですね(笑)
WAFといわず、CloudFront自体の落とし穴というか。
■國友
こちら側のアプリケーションの作りの問題と言ってしまえばそれまでですが、とはいえ、知見としては広めたいですね。
■与儀
CloudFrontの制約に関してこちらも前もってお知らせできれば良かったのですが・・・。
■國友
アプリケーションの作りに問題があるということまでは予想はできないことだと思いますので・・・。
■加藤
システム自体が古いので・・・。
■下門
この問題に対する代替手段としてはどのように対応したのでしょうか?
■國友
そうですね。与儀さんの方ですぐにホスト型のWAF兼IPS/IDSのソリューションを選定・検証していただきました。すぐに試用版を入れられるということでしたので、いったんこのソリューションを入れていただき、その間に他の手段も比較検討しつつ、問題なければそのまま進めようと。結果的に選定いただいたソリューションを採用しました。
第2回に続きます!
■河村
ありがとうございました。では、まずはこれくらいで第1回目は終わりたいと思います。
皆さん第2回もよろしくお願いします!
【関連リンク】
オウチーノさまの採用情報はこちらから!!!↓↓↓
https://www.wantedly.com/companies/o-uccino/projects