Deep learning printed characters
2016年5月31日 火曜日 | BIZ & TECH LEXUES 社員の趣味
Hi everyone
Kuba from Planning & Development Section here.
Since last December I have been studying deep learning in my spare time. While there is a great variety of tasks to which it can be applied, for my first personal project I decided on a modest one – recognizing printed characters.
To keep things simple, I am restricting myself to a single font and individual characters bounded by a box, much like Kotobanban does. For those of you not familiar with Kotobanban – it’s a fun, educational game capable of recognizing hiragana characters printed on playing cards. Kotobanban does its tasks of detecting ~80 characters extremely well. However, having authored the character recognition engine of Kotobanban, I’m well aware of its limitations. It could handle other simple symbols, like Latin characters, digits or katakana, but its hand-crafted features recognition system would fail on even modestly complicated kanji. And I really wanted to write a system capable of handling kanji as well.
So over last weekend I trained myself a neural network that would do for me just that! Here’s the setup: I first prepared templates of characters I wanted to recognize. For now that’s about ~250 characters consisting of Latin alphabet, digits, hiragana, katakana and all Jouyou Level 1 kanji. Templates are simple 32×32 images of each character, e.g.
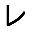
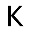
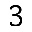
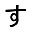

Then for each template I created 1000 images that would contain random perturbations of original image, adding pepper noise, rotation, translation, perspective projection and intensity variation. This would yield images like ones below

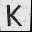



I partitioned above data into training and test sets using an 80%-20% split. Having these ready I could go about training my network! I used a [pixel count, 100, 100, labels count] fully connected network and a learning rate of 0.01. And the result? An impressive 99.53% accuracy on test data after barely 100 training epochs! And that’s even before applying regularization, drop-out, trying alternative activation functions, more layers, etc.
And should I worry about the remaining ~0.5% I didn’t get right? Nope, I don’t think so. When capturing characters bounding boxes, like Kotobanan does, character images are reconstructed to representations that only slightly diverge from their templates. In other words my real data will be far less noisy than artificially tinkered images above. I still have to code the image reconstruction module to be able to confirm my assumptions and beat Kotobanban, but results so far are very encouraging.